हेलो दोस्तों आज के इस पोस्ट में हम आपको Hadoop के बारे में जानकारी देंगे, जैसे की हडूप क्या है, What is Hadoop in Hindi और इसके Advantages के बारे में भी जानेंगे, तो बिना देर करे चलिए शुरू करते हैं।
जैसे की आप जानते हैं आज के इस डिजिटल युग में डाटा की एक महत्वपूर्ण भूमिका है, चाहे वह हमारा व्यक्तिगत डाटा हो, एप्लीकेशन द्वारा तैयार डाटा हो, Statistical डाटा हो या फिर किसी बहुराष्ट्रीय (Multinational) कंपनी का डाटा, हर प्रकार के डाटा का अपना महत्व है।
और डाटा का यह महत्व किसी व्यक्ति या कंपनी तक ही सीमित नहीं है, बल्कि यह मार्किट की स्थिति को बदलने में भी सक्षम है।
इसी प्रकार विभिन्न श्रोतो से प्राप्त यह डाटा एक विशाल रूप ले लेता है जो की Big data कहलाता है, तो बढ़ते जा रहे डाटा के इस विशाल आकार का रखरखाव (Maintenance) करना, डाटा की Processing करना और उसे analyze करना एक आवश्यक प्रक्रिया होती है और इसी प्रक्रिया के लिए Hadoop का उपयोग किया जाता है।
हडूप क्या है। What is Hadoop in Hindi
हडूप Apache सॉफ्टवेयर की बुनियाद पर बना एक framework है, इस लिए इसे Apache Hadoop भी कहा जाता है। यह एक Open source सॉफ्टवेयर प्रोग्रामिंग फ्रेमवर्क है, जिसका उपयोग डाटा के विशाल आकार (Big data) को कुशलता पूर्वक store करने, process करने थता analyze करने के लिए किया जाता है, इसीलिए Hadoop को बिग डाटा का Backbone भी कहा जाता है।
Hadoop प्रोग्रामिंग फ्रेमवर्क को java में लिखा गया है और इसकी सबसे महत्वपूर्ण बात यह है की यह Big data प्रोसेसिंग और Storage के लिए distributed Computing environment का उपयोग करता है, जहाँ पर एक ही समय में Multiple computer’s पर डाटा स्टोरेज, उसकी प्रोसेसिंग थता एनालसिस काफी तेजी से चलती रहती है।
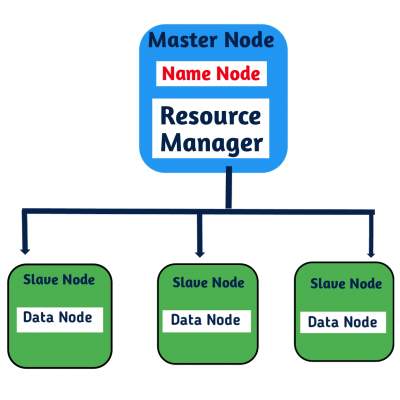
Hadoop Architecture in Hindi
हडूप आर्किटेक्चर Master-slave टोपोलॉजी पर आधारित है, जिसमे एक Master node होता है और उसके विभिन्न Slave nodes होते हैं। Master node का कार्य सभी Slave nodes को task सौंपना थता resources को Manage करना होता है, यानि सही रूप में Slave nodes द्वारा ही असल Processing/Computing की जाती है।
जहाँ तक डाटा को स्टोर करने की बात की जाए तो मास्टर नोड द्वारा सिर्फ Metadata को ही स्टोर किया जाता है, मेटाडाटा यानि ऐसा डाटा जिसमे किसी दूसरे डाटा के बारे में जानकारी दी गई हो (data about data) जैसे file name, file permission, IDs, locations इत्यादि, जबकि Slave nodes द्वारा real data को स्टोर किया जाता है।
Hadoop architecture के अन्तर्गत तीन लेयर्स शामिल होती हैं जो निम्नलिखित हैं।
Storage layer (HDFS)
Resource Management layer (YARN)
Processing layer (MapReduce)
यह तीनो ही हडूप फ्रेमवर्क के महत्वपूर्ण components हैं, तो चलिए इन्हे एक-एक कर समझते हैं।
Hadoop HDFS:- (HDFS) Hadoop distributed file system, हडूप इकोसिस्टम का एक प्रमुख और मुख्य कॉम्पोनेन्ट है, जो high volume डाटा को distributed तरीके से store करने का काम करता है, जिसमे डाटा को Cluster nodes में बाँट दिया जाता है।
यानि logicall रूप से HDFS डाटा स्टोरेज का एक single unit नजर आता है, लेकिन असल में डाटा multiple nodes में स्टोर रहता है।
HDFS मास्टर-स्लेव आर्किटेक्चर पर कार्य करता है, जहाँ पर दो प्रकार के Nodes होते हैं,पहला है Namenode जो की master node होता है और बाकि होते हैं Datanodes जो की Slave nodes होते हैं।
Namenode
नैमनोड (HDFS) हडूप डिस्ट्रीब्यूशन सिस्टम का केंद्र है, इसे मास्टर नोड भी कहा जाता है, यह datanodes यानि Slave nodes में मौजूद blocks को maintain और manage करता है।
NameNode
- यह सिर्फ HDFS के metadata को ही save रखता है।
- इसके द्वारा फाइल सिस्टम namespace को मैनेज किया जाता है।
- यह Actual data या datasets को स्टोर नहीं करता है।
- Namenode सिर्फ HDFS में मौजूद ब्लॉक्स और उनकी locations को मैनेज करता है।
- यह data nodes (Slave) को कार्य सौंपता है।
- यह HDFS के लिए काफी महत्वपूर्ण होता है क्योंकि यदि Namenode काम करना बंद कर देता है, तो ऐसे में पूरे HDFS को ही डाउन माना जाता है।
DataNode - HDFS इकोसिस्टम में datanode ही real data को स्टोर रखते हैं।
- Datanodes को Slave कहा जाता है, जो की कार्यकर्त्ता के रूप में होते हैं, यानि इनके द्वारा read/write और processing की जाती है।
- Datanode थता Namenode आपस में लगातार कम्यूनिकेट करते हैं।
- यह Namenode द्वारा आदेश प्राप्त करता है और उसी अनुसार कार्य करता है।
- Datanode को बड़ी मात्रा में storage सुविधा की आवश्यकता पड़ती है, क्योंकि इनके द्वारा डाटा स्टोर किया जाता है।
Yarn:- इसका full form है Yet another resource Negotiator, यह task को schedule करता है, उन्हें मैनेज करता है थता Cluster nodes और दूसरे resources को monitor करता है। Yarn का मुख्य कार्य job scheduling और Cluster management का है और यह एक Component के तोर पर Hadoop version 2 में उपलब्ध है।
MapReduce
यह एक सॉफ्टवेयर फ्रेमवर्क है जिसके द्वारा ऐसी ऍप्लिकेशन्स लिखी जाती हैं, जिन्हे hadoop ecosystem में run कर संके और MapReduce के यह प्रोग्राम डाटा के विशाल रूप को parallel रूप से processes करने में मदद करते हैं। MapReduce के दो मुख्य phase होते हैं Map phase थता Reduce phase.
Map phase डाटा को blocks के रूप में स्टोर करता है, इसमें डाटा को read और processes किया जाता है और एक key value pair दिया जाता है। इसके बाद Reduce phase इस key value pair को map phase से प्राप्त करता है और processing के बाद output निकल के आता है।
Advantage of Hadoop in Hindi
- हडूप एक open source सॉफ्टवेयर प्रोग्रामिंग फ्रेमवर्क है, इसका source code freely उपलब्ध है और इसमें अपनी जरुरत अनुसार Modification किए जा सकते हैं।
- हडूप इकोसिस्टम में डाटा Cluster में distribute होता है, और parallel रूप से डाटा की प्रोसेसिंग होती है, जिससे processing में लगने वाला समय काफी कम हो जाता है, इसलिए यह डाटा के विशाल आकार को काफी कम समय में प्रोसेस कर सकता है।
- Cluster के आकर को कभी भी बढ़ाया जा सकता है यानि इसमें nodes की संख्या को बढ़ाया जा सकता है।
- हडूप डाटा के विभिन्न प्रकार को accept करता है फिर चाहे वह Structured data हो या Unstructured.
- हडूप Cost effective है और एक किफायती solution है, क्योंकि यह Open source होने के साथ-साथ डाटा स्टोरेज के लिए Commodity hardware का उपयोग करता है, जो की dedicated स्टोरेज सर्वर की तुलना में काफी सस्ते पड़ते हैं।
अंतिम शब्द
दोस्तों आपने जाना हडूप क्या है, What is hadoop in Hindi और यह किस प्रकार काम करता है, हमें उम्मीद है दी गयी यह जानकारी आपको अच्छी लगी होगी। यदि पोस्ट आपको ज्ञानवर्धक लगी है, तो इस ज्ञान को दूसरों तक भी पहुँचाए धन्यवाद।